Data science for better treatment of leukemia. |

|
John Jacobs
30 juli 2020
Jacqueline Cloos of the Amsterdam University Medical Center studies hematological cancers for the development of algorithms that can be implemented in clinical decision support tools to optimize treatment choices. ORTEC offers added value to this mathematical and statistical research with LogiqCare and the Big Data Portal.
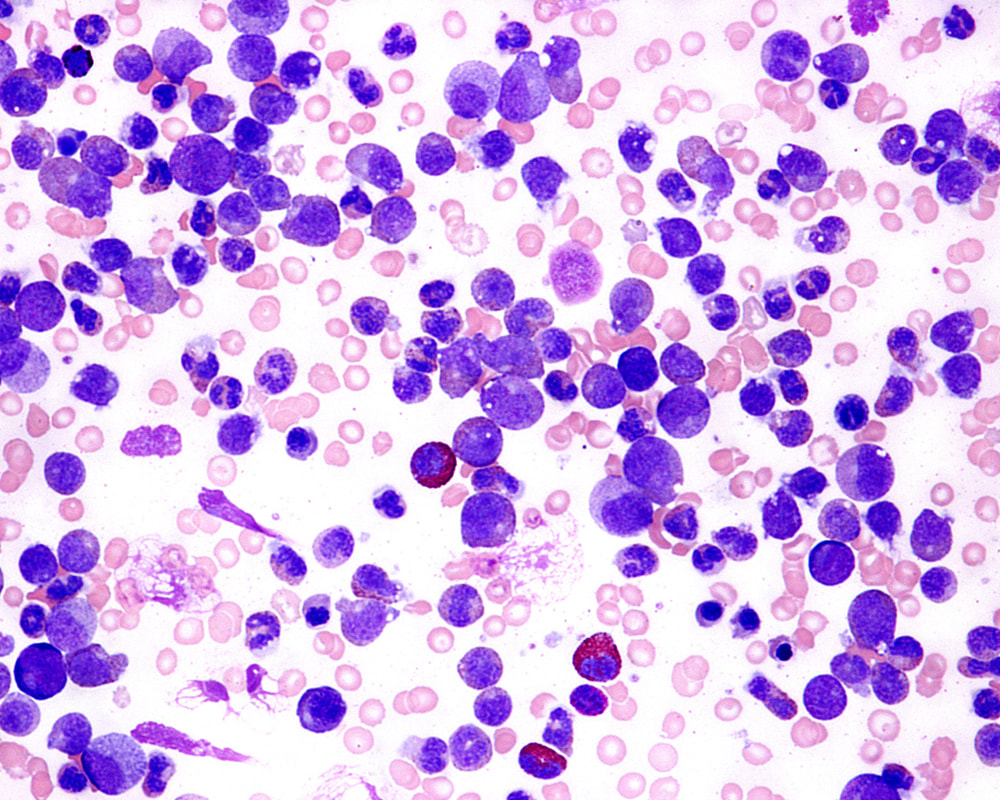
Figure 1. Acute Myeloid Leukemia in Blood
Acute Myeloid Leukemia (AML; Figure 1) accounts for 1-2% of all tumor-related deaths. This form of cancer can occur at all ages, but the incidence of AML rises with age. Survival without treatment is on average about half a year. Treatment of AML consists of multiple cycles of intensive chemotherapies and depending on the risk of relapse also autologous or allogenic stem cell transplantation. For the choice of the latter the relatively high treatment-related mortality (2% to more than 10%) has to be taken into account. AML has considerable heterogeneity in underlying genetics, mechanisms, and patient-related characteristics. The five-year survival varies from 15 to 70% depending on risk-group classification. Patients with different forms of AML need different therapeutic interventions for optimal survival. In conventional medicine, AML was considered a single disease, with limited therapeutic progress (Figure 2).
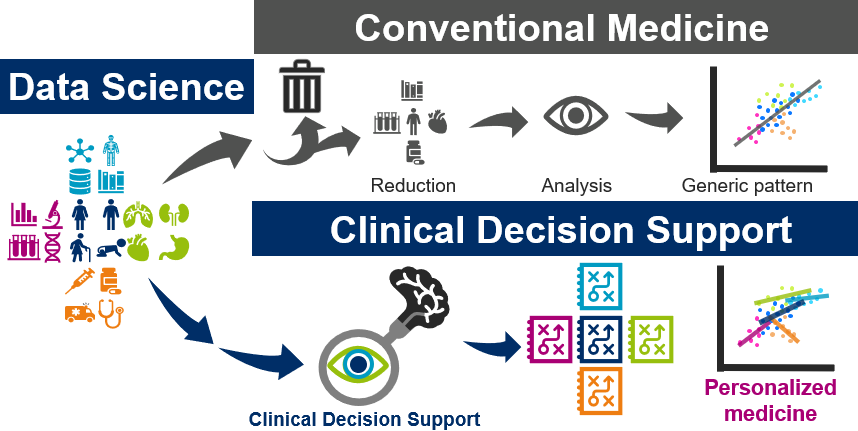
Figure 2. In conventional medicine complex data are reduced prior analytics. In personalized medicine, complex data are differentially analyzed in different interventions to optimize therapy for each patient group independently.
Personalized medicine
Personalized medicine and personalized risk classification to identify patients at risk for developing a relapse is currently suboptimal and relies on characteristics of patients, their treatment responses, tumor cytogenetics and mutations. The aim is to develop an accurate prediction model to improve risk assessment and survival of patients after the first induction chemotherapy cycles to determine the best therapeutic regime. Within patient’s disease follow-up should be compared between patients with similar molecular and/or immunological characterization of their tumors. This includes follow-up of changes in the characterization of minimal residual disease (MRD), i.e. the presence of deviant blood cell precursors that might be tumor cells. Structuring complex data is a high-level specialization from medical research requiring integration of the medical, mathematical and ICT insights. The aim is to differentially analyze the complex data to determine which parameters relate with outcomes for various therapies to improve and further personalize AML treatment.
Toolbox
ORTEC structures complex medical data from various sources, like centralized patient follow-up and experimental laboratory data on various tumor markers and their numbers in time. Patient data from various source databases are transferred to LogiqCare through the Extract-Transform-Load (ETL) process. These patient data are synced anonymously in the Big Data Portal to have structured data ready for Spotfire analysis for mathematical and statistical research on the structured data. Other research groups from Europe and beyond have expressed their interest to cooperate in this data research project. The aim is to develop algorithms that will be implemented for clinical decision support tools to optimize treatment decisions by physicians and patients.
Below is a link to a video of a master student math working on this AML project.
John Jacobs, 30th of july 2020
